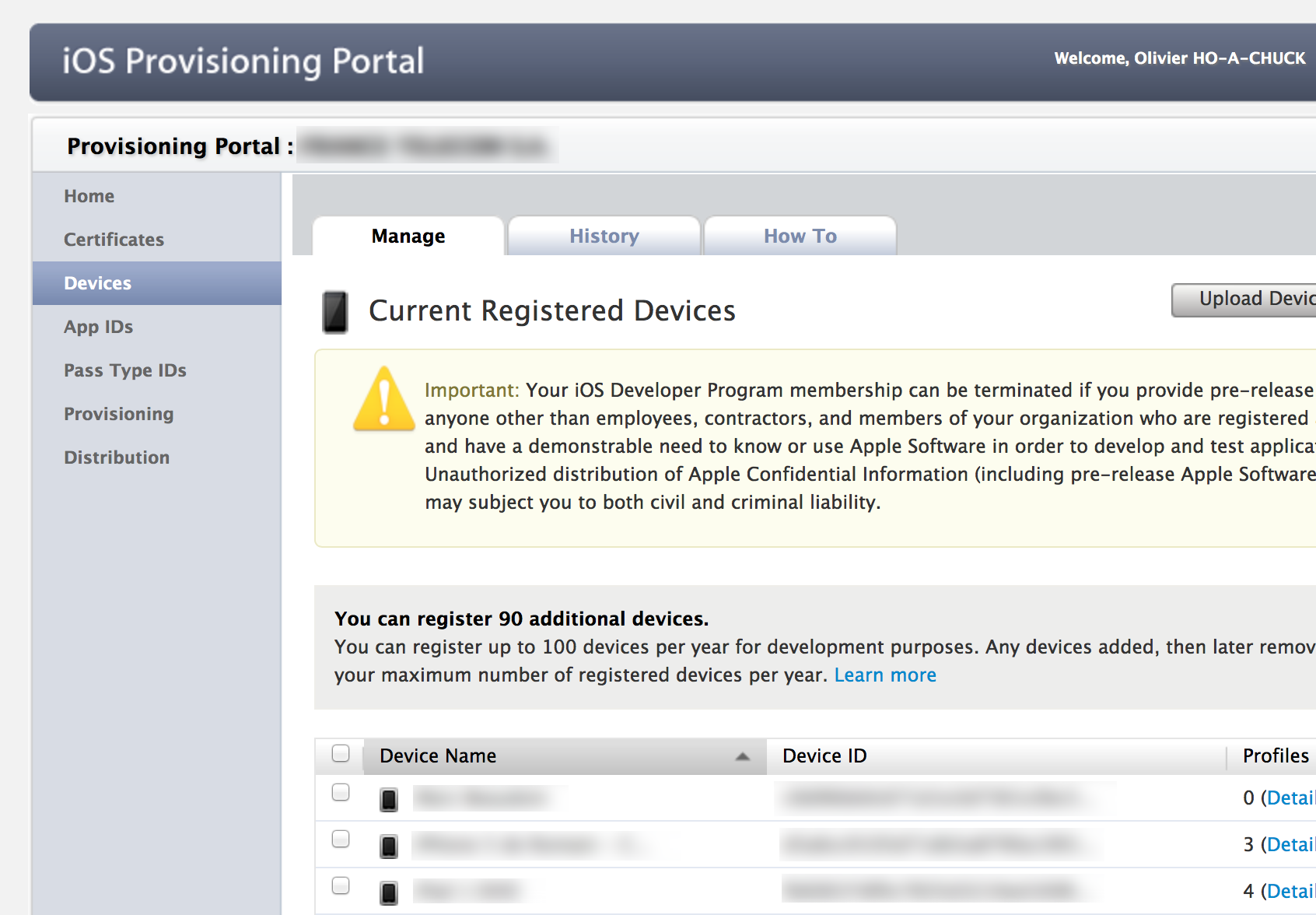
Every years, iOS developers have the opportunity to clean it’s udid entries from iOS Provisionning Portal. Everytime you have to do this, it’s always good to keep a track of what was currently setup before to clean it all. At least to have in mind who you might ask if their devices are still valid or if they have upgraded to the latest iPhone (meaning the old UDID does not need now to be filling the 100 limit for registred devices).
For some times, I had a quick and dirty command line that used to just extract the UDID list without associated holder name. Now I have writen a litle python script that could extract the UDID list but also the associated label name.
A quick and dirty command ligne that extract the list of UDID
if you go to developer Portal on Device section and save the current page to “udid.html”, you can use the following command with regex to exctract the UDIDs.
perl -000 -lne 'print $1 while /\<td class="id"\>(.+?)\<\/td\>/sg' udid.html
My first try of Eclipse environment was to write this Python3 script that could parse the exported udid.html file.
The big advantage of using Eclipse is that you can easily debug your code.
When you parse html pages, it’s just a must have feature to undrestand what exactly you need to find and match.
I remember having headaches while trying to retreive my way on a complex page parsing using xpath…
To start my script I have used the Module-CLI-optparse existing template (that I have modified a bit to work with Python3).
So the script look heavy and complicated but it’s because of the all option management.
To be able to use this script you’ll need to install BeautifulSoup 4 - if not yet installed:
#!/usr/local/bin/python3# encoding: utf-8''' -- getudid-arg.py This script is used to gather the list of UDID from iOS Provisionning portal usage is: getudid-arg.py -i "udid.html" -o "output.csv"@author: Olivier HO-A-CHUCK@copyright: 2013 Olivier HO-A-CHUCK. All rights reserved.@license: Apache 2@contact: olivier.hoachuck@gmail.com@deffield updated: Updated'''importsysimportosfrombs4importBeautifulSoupfromoptparseimportOptionParser__all__=[]__version__=0.1__date__='2013-02-20'__updated__='2013-02-20'DEBUG=0defmain(argv=None):'''Command line options.'''program_name=os.path.basename(sys.argv[0])program_version="v0.1"program_build_date="%s"%__updated__program_version_string='%%prog %s (%s)'%(program_version,program_build_date)# program_usage = '''usage: spam two eggs''' # optional - will be autogenerated by optparseprogram_longdesc=''''''# optional - give further explanation about what the program doesprogram_license="Copyright 2013 Olivier HO-A-CHUCK (OHO Consulting) \ Licensed under the Apache License 2.0\nhttp://www.apache.org/licenses/LICENSE-2.0"ifargvisNone:argv=sys.argv[1:]try:# setup option parserparser=OptionParser(version=program_version_string,epilog=program_longdesc,description=program_license)parser.add_option("-i","--in",dest="infile",help="set input path [default: %default]",metavar="FILE")parser.add_option("-o","--out",dest="outfile",help="set output path [default: %default]",metavar="FILE")parser.add_option("-v","--verbose",dest="verbose",action="count",help="set verbosity level [default: %default]")parser.add_option("-s","--string",dest="input_string",help="set input string to parse. When this is set, result is sent to standard output")# set defaults# parser.set_defaults(outfile="./udid-export.csv", verbose=0)parser.set_defaults(verbose=0)treatment=""# process options(opts,args)=parser.parse_args(argv)ifopts.infileandopts.input_string:parser.error("You have to choose between -i and -s option (input have to be either a file or either a string. Not both! Type "+sys.argv[0]+" -h for more options")ifopts.input_string:# print("input is a string: %s" % opts.input_string)treatment="STRING"ifopts.verbose>0:print("verbosity level = %d"%opts.verbose)ifopts.infile:treatment="FILE"else:parser.error("Missing argumants. Try -h option!")# if opts.outfile:# pass# MAIN BODY ## print os.environ["PYTHONPATH"]iftreatment=="FILE":print("Processing mode is \"file input\"")print("input file = %s"%opts.infile)# print("output file = %s\n" % opts.outfile)udid_file=open(opts.infile,"r",encoding='utf-8')content=udid_file.read()ifopts.outfile:output_file=opts.outfileprint("output file = %s\n"%output_file)else:editor_name=getEditor(content)output_file="UDIDs - "+editor_name+".csv"ifopts.verbose>0:print("output file = %s\n"%output_file)udid_export_file=open(output_file,"w",encoding='utf-8')udid_couple=doParse(content)ifudid_couple=="":print("NO UDIDs found! Are you sure you feed the script with an iTunes Connect correct page content?")ifopts.verbose>0:print(udid_couple)udid_export_file.write(udid_couple)udid_export_file.close()# print("Done!\nUse \"-v 1\" option for more details")else:udid_couple=doParse(opts.input_string)ifudid_couple=="":print("NO UDIDs found! Are you sure you feed the script with an iTunes Connect correct page content?")# return 2ifopts.verbose>0:print(udid_couple)exceptExceptionase:indent=len(program_name)*" "sys.stderr.write(program_name+": "+repr(e)+"\n")sys.stderr.write(indent+" for help use --help\n")return2defdoParse(content=""):soup=BeautifulSoup(content)udid_couple=""forrowinsoup.findAll('td',{'class':'id'}):try:iflen(row.parent.span.string)==25:device_name=row.parent.span.attrs['title']else:device_name=row.parent.span.stringudid_couple+=row.string+";"+device_name+"\n"except:passreturnudid_coupledefgetEditor(content=""):soup=BeautifulSoup(content)editor_name=""try:editor_name=soup.find('div',{'id':'main'}).find('div',{'id':'top'}).find('span').stringexcept:passreturneditor_nameif__name__=="__main__":ifDEBUG:# sys.argv.append("-h")sys.argv.append("-i")sys.argv.append("/Users/oho/Desktop/udid.html")sys.argv.append("-v")sys.argv.append("1")sys.exit(main())
This script have certainly room of optimisation (may be bugs) and as I’m a newby in Python, it’s probably not the most efficient code you’ll find,
but it works and was a good simple test use case for me to keep trying on Python dev.
AppleScript service for calling the script from safari
Just to make it more convenient, I have pushed it further to be able to run the script from the browser directly while being on iOS Provisionning Portal.
For this I have created a mac service
that is available when you are on Safari only (Safari Menu -> Services -> Safari-GetUDID).
To make this service available on Safari, just download Safari-GetUDID.workflow and copy it to your User Library/Services folder.
Before to run this little service, make sure you change at the bottom of the AppleScript workflow, the path that must fit your personal environments.
12
# Current line that need customisation:set result to do shell script "export PYTHONPATH=/usr/local/lib/python3.3/site-packages; /usr/local/bin/python3 /Users/oho/mbin/getudid-arg.py -i /Users/oho/Desktop/udid.html -o /Users/oho/Desktop/" & output_filename & ".csv"
Hard time with Chrome to retreive and save to file an html page content
I did not wanted to spend to much time in those 2 scripts. So I had to make coding
choices that would let me go quickly. That’s why there are probably lot’s of missing optimisation or wrong
stuffs you guys could detect and point me out.
The big think I found while trying to make this work is that it was a paintful process to have the Chrome Script service while Safari was done in few minutes.
If you succeed in porting this little service to Chrome, I’ll be happy you post it here how and/or contact me.
Indeed I mostly use Chrome but Safari on a daily basis.
Conclusion
Ok, I know! A command line with REGEX to gather UDIDs would probably be enough for a once or twice a year usage.
But in the present case, it’s more the implementation of Python3 code with BeutifulSoup html parsing kind of thing wich had really excited my curiosity while playing around on debug mode over Python script using Eclipse. The development potential with this environment setup looks very promessing…